Try out ValidMind Academy
Our training modules are interactive. They combine instructional content with our live product and are easy to use.
On top of our increased support for tests and arrays in the ValidMind Library and our first ValidMind Academy training modules, we’ve introduced customizable model workflows, new role functionality, and new report types.
You can now run comparison tests with the ValidMind Library.
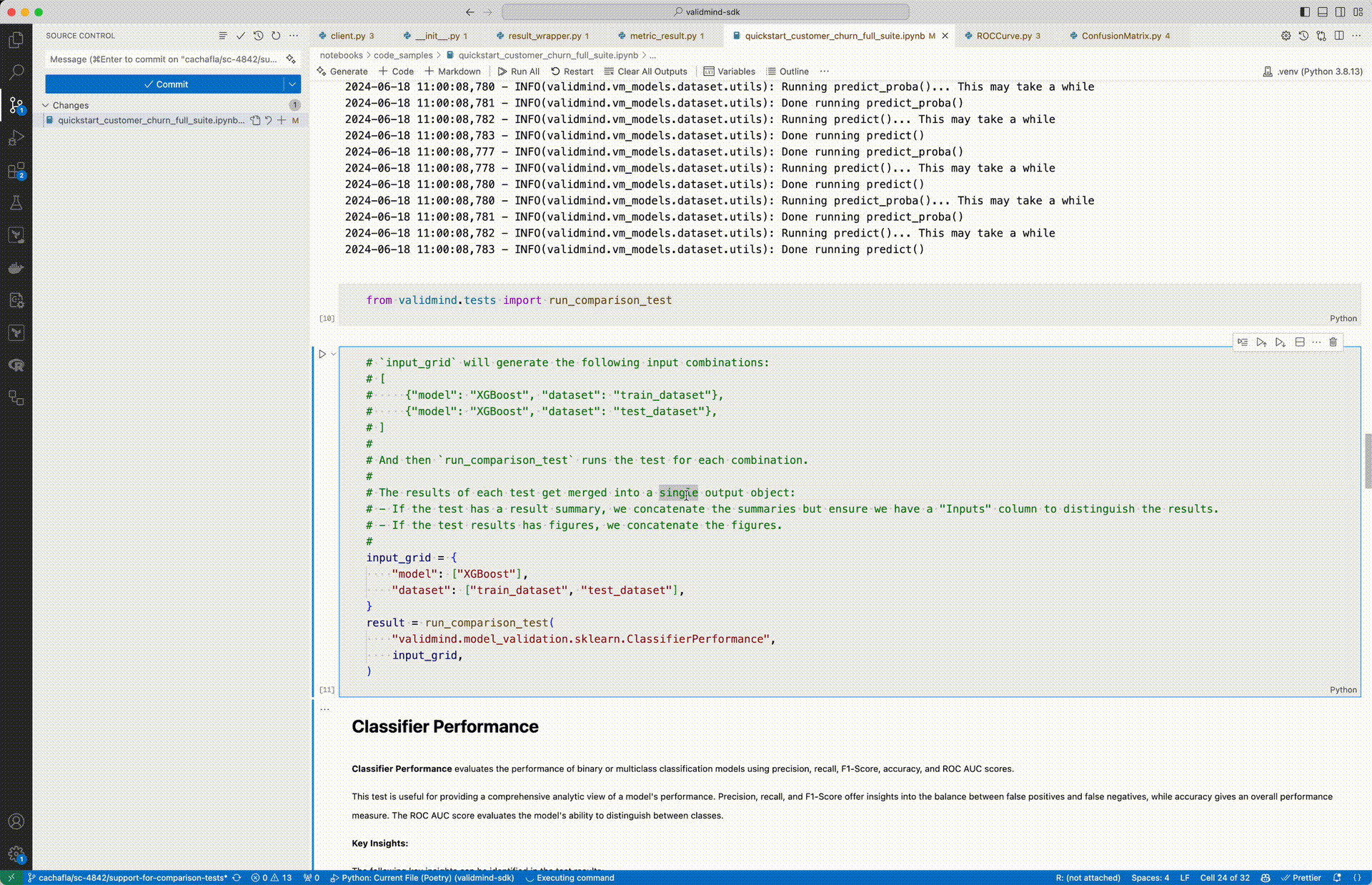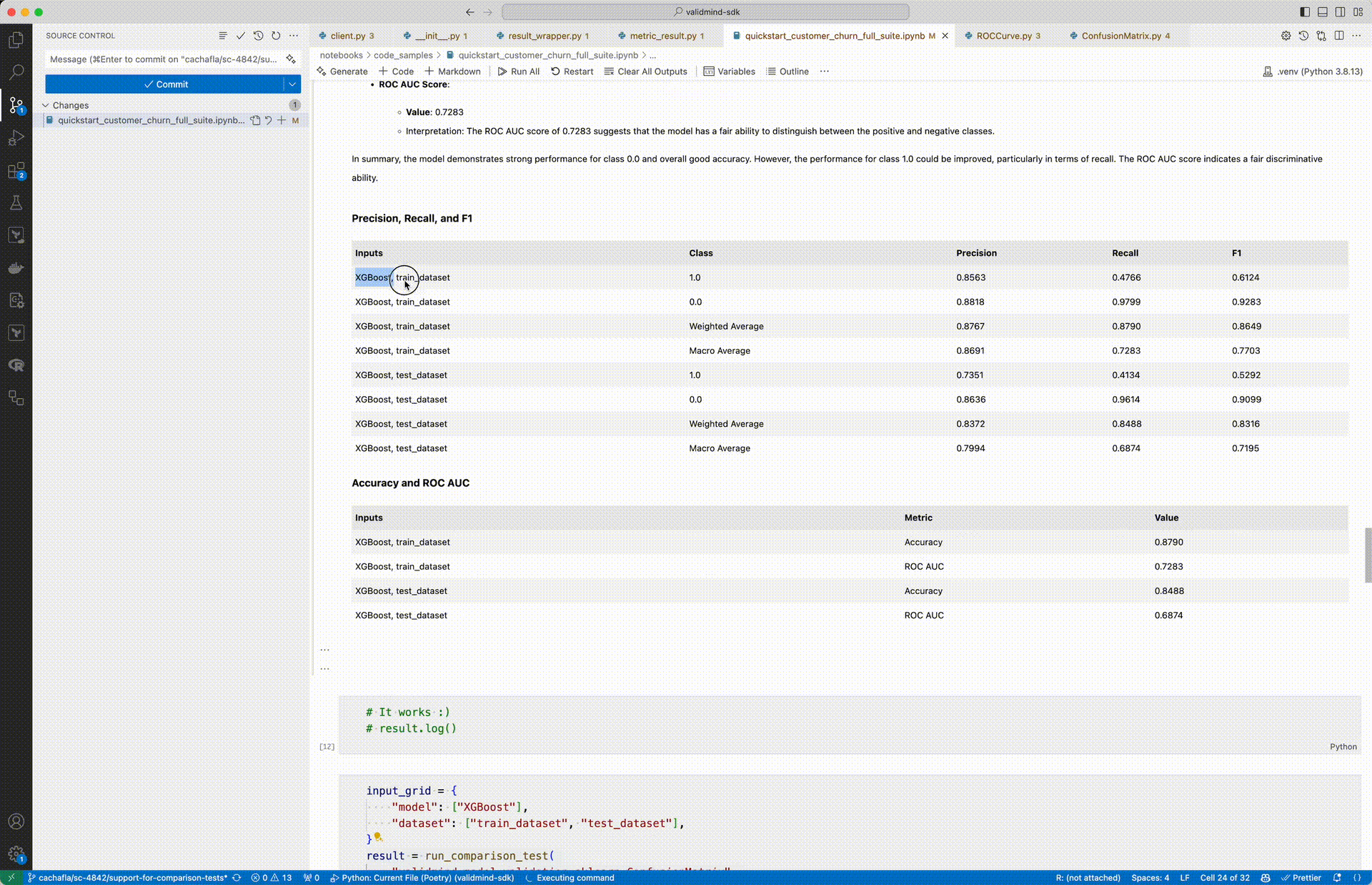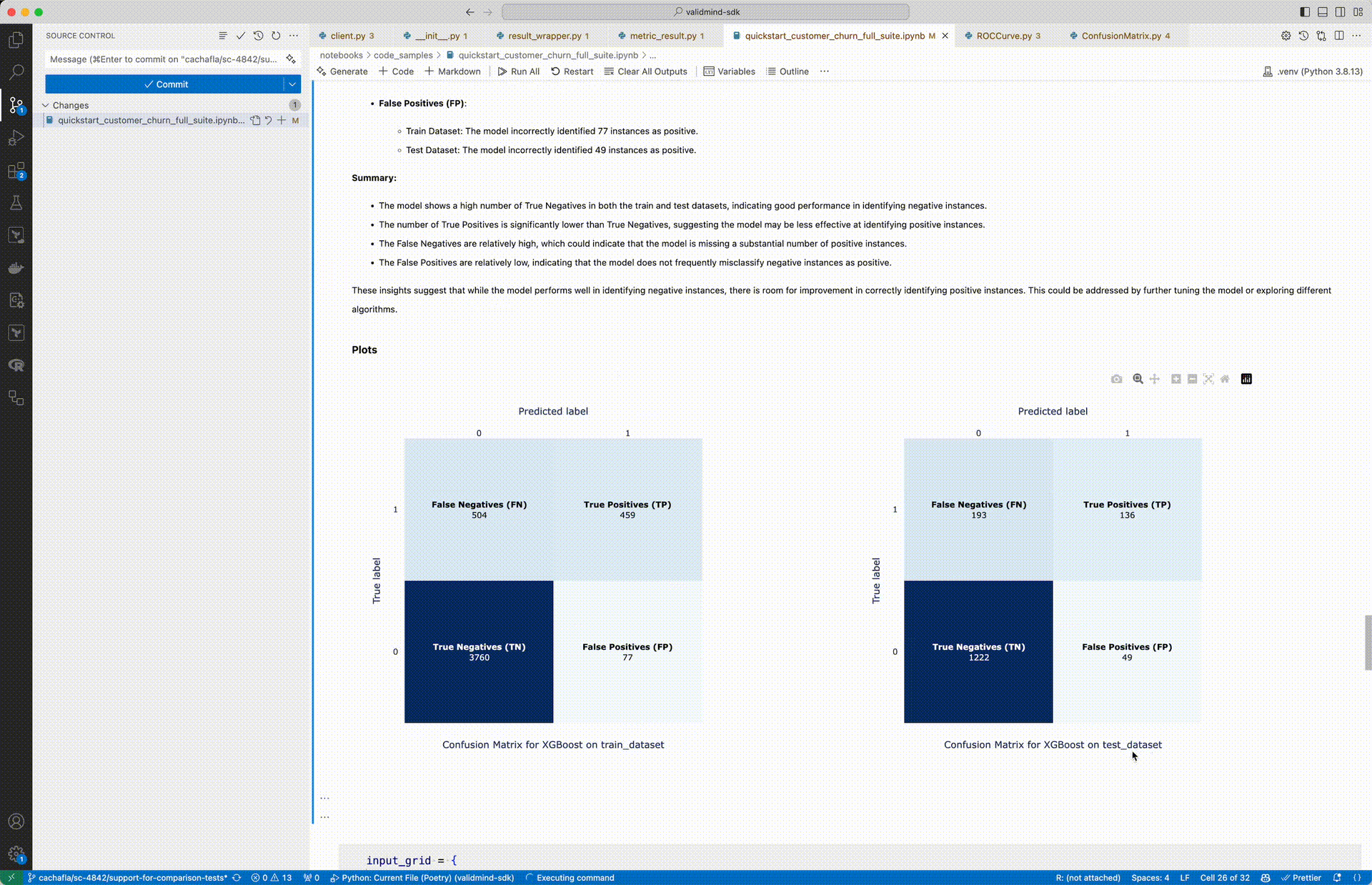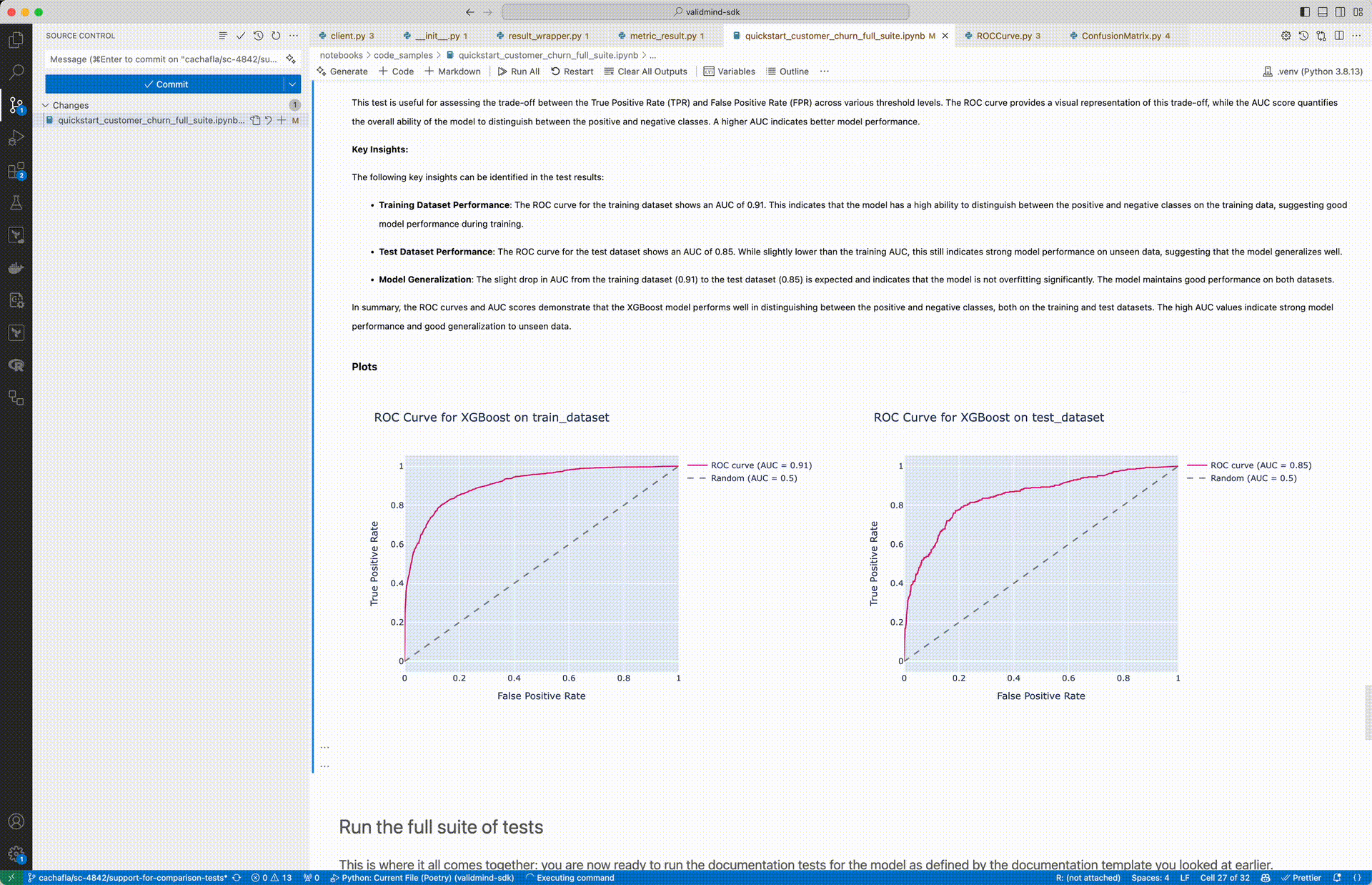
The updated run_test() function allows you to pass an input_grid which runs a test for all combinations of inputs.
input_grid = {
"model": ["XGBoost"],
"dataset": ["train_dataset", "test_dataset"],
}A test runs once for each of the following input groups:
{
"model": "XGBoost",
"dataset": "train_dataset"
}
{
"model": "XGBoost",
"dataset": "test_dataset"
}from validmind.tests import run_test
input_grid = {
"model": ["XGBoost"],
"dataset": ["train_dataset", "test_dataset"],
}
result = run_test(
"validmind.model_validation.sklearn.ClassifierPerformance",
input_grid,
)
result = run_test(
"validmind.model_validation.sklearn.ConfusionMatrix",
input_grid,
)
result = run_test(
"validmind.model_validation.sklearn.ROCCurve",
input_grid,
)You can now manage lifecycle processes within your ValidMind Platform setup using customizable model workflows.
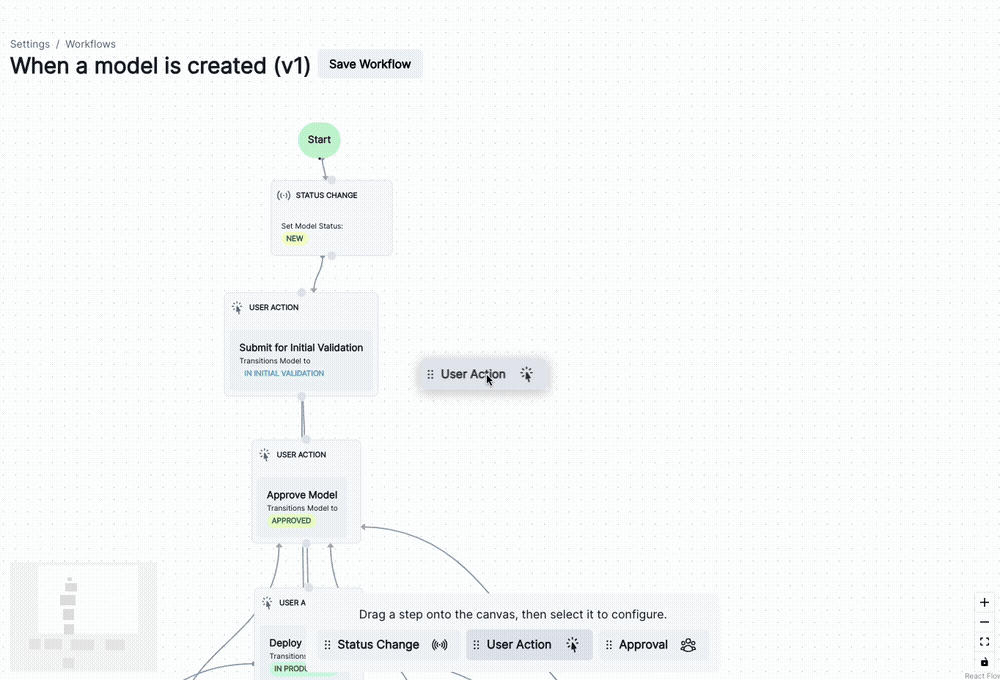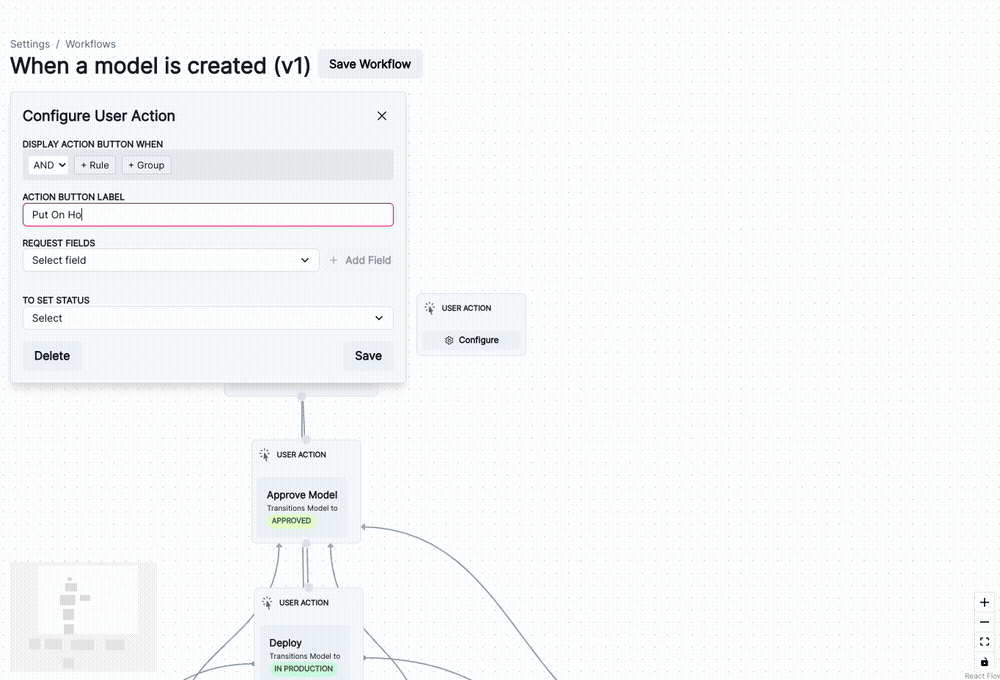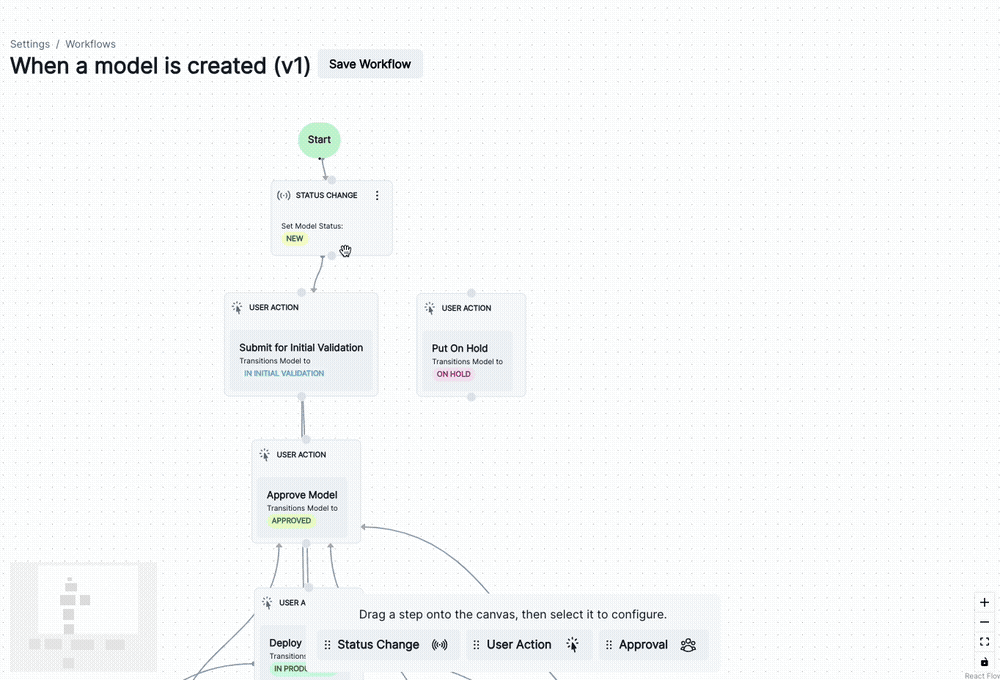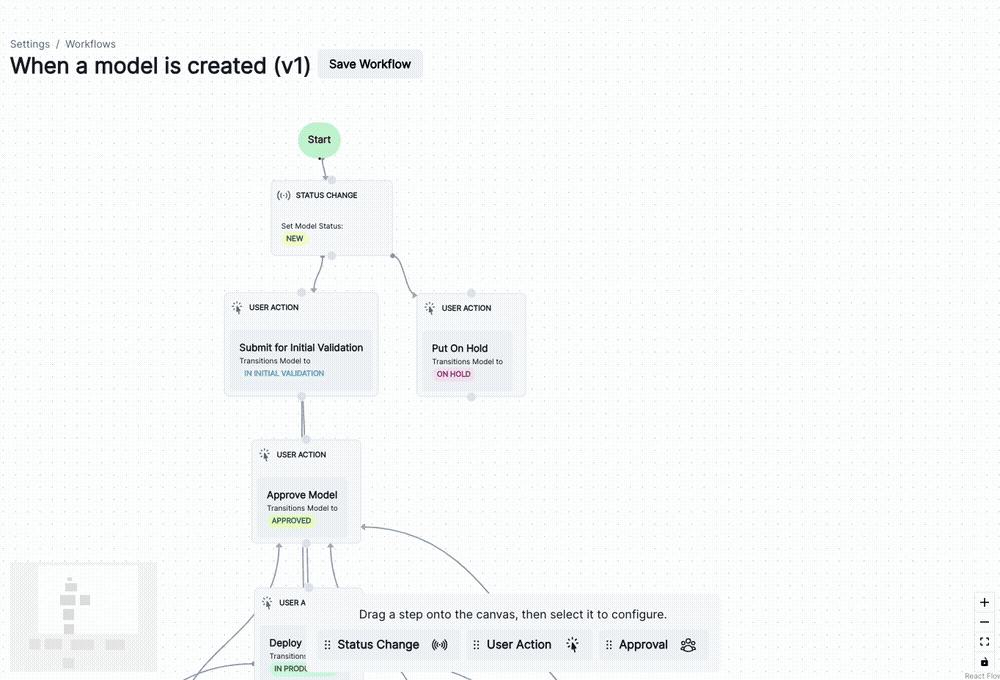
add_extra_columnVMDataset class, the add_extra_column() method now supports adding 2D arrays as single columns in the dataset’s DataFrame.For example:
import numpy as np
import pandas as pd
# sample DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
# sample 2D array
array_2d = np.array([
[1, 2],
[3, 4],
[5, 6]
])
vm_dataset = vm.init_dataset(
dataset=df,
input_id=dummy_ds
)
vm_dataset.add_extra_columns(
"dummy_column",
array_2d
)Users with the Create Role permission can now add a new role under Settings.
We added a number of new report types:
We fixed a number of missing test descriptions that were caused by a scripting issue.
We’re introducing the first training modules that are part of our ValidMind Academy training program for:
To access the latest version of the ValidMind Platform,1 hard refresh your browser tab:
Ctrl + Shift + R OR Ctrl + F5⌘ Cmd + Shift + R OR hold down ⌘ Cmd and click the Reload buttonTo upgrade the ValidMind Library:2
In your Jupyter Notebook:
Then within a code cell or your terminal, run:
%pip install --upgrade validmindYou may need to restart your kernel after running the upgrade package for changes to be applied.