%pip install -q validmindDocument an Excel-based application scorecard model
Build and document an Excel-based application scorecard model with the ValidMind Library. Learn how to load an Excel-based model, prepare your datasets and model for testing, run tests and log those test results to the ValidMind Platform.
An application scorecard model is a type of statistical model used in credit scoring to evaluate the creditworthiness of potential borrowers by generating a score based on various characteristics of an applicant such as credit history, income, employment status, and other relevant financial data.
- This score assists lenders in making informed decisions about whether to approve or reject loan applications, as well as in determining the terms of the loan, including interest rates and credit limits.
- Effective validation of application scorecard models ensures that lenders can manage risk efficiently while maintaining a fast and transparent loan application process for applicants.
About ValidMind
ValidMind is a suite of tools for managing model risk, including risk associated with AI and statistical models.
You use the ValidMind Library to automate documentation and validation tests, and then use the ValidMind Platform to collaborate on model documentation. Together, these products simplify model risk management, facilitate compliance with regulations and institutional standards, and enhance collaboration between yourself and model validators.
Before you begin
This notebook assumes you have basic familiarity with Python, including an understanding of how functions work. If you are new to Python, you can still run the notebook but we recommend further familiarizing yourself with the language.
If you encounter errors due to missing modules in your Python environment, install the modules with pip install, and then re-run the notebook. For more help, refer to Installing Python Modules.
New to ValidMind?
If you haven't already seen our Get started with the ValidMind Library, we recommend you begin by exploring the available resources in this section. There, you can learn more about documenting models, find code samples, or read our developer reference.
For access to all features available in this notebook, you'll need access to a ValidMind account.
Register with ValidMind
Register with ValidMind
Key concepts
Model documentation: A structured and detailed record pertaining to a model, encompassing key components such as its underlying assumptions, methodologies, data sources, inputs, performance metrics, evaluations, limitations, and intended uses. It serves to ensure transparency, adherence to regulatory requirements, and a clear understanding of potential risks associated with the model’s application.
Documentation template: Functions as a test suite and lays out the structure of model documentation, segmented into various sections and sub-sections. Documentation templates define the structure of your model documentation, specifying the tests that should be run, and how the results should be displayed.
Tests: A function contained in the ValidMind Library, designed to run a specific quantitative test on the dataset or model. Tests are the building blocks of ValidMind, used to evaluate and document models and datasets, and can be run individually or as part of a suite defined by your model documentation template.
Custom tests: Custom tests are functions that you define to evaluate your model or dataset. These functions can be registered via the ValidMind Library to be used with the ValidMind Platform.
Inputs: Objects to be evaluated and documented in the ValidMind Library. They can be any of the following:
- model: A single model that has been initialized in ValidMind with
vm.init_model(). - dataset: Single dataset that has been initialized in ValidMind with
vm.init_dataset(). - models: A list of ValidMind models - usually this is used when you want to compare multiple models in your custom test.
- datasets: A list of ValidMind datasets - usually this is used when you want to compare multiple datasets in your custom test. See this example for more information.
Parameters: Additional arguments that can be passed when running a ValidMind test, used to pass additional information to a test, customize its behavior, or provide additional context.
Outputs: Custom tests can return elements like tables or plots. Tables may be a list of dictionaries (each representing a row) or a pandas DataFrame. Plots may be matplotlib or plotly figures.
Test suites: Collections of tests designed to run together to automate and generate model documentation end-to-end for specific use-cases.
Example: The classifier_full_suite test suite runs tests from the tabular_dataset and classifier test suites to fully document the data and model sections for binary classification model use-cases.
Setting up
Install the ValidMind Library
Recommended Python versions
Python 3.8 ≤ x ≤ 3.11
To install the library:
Initialize the ValidMind Library
Register sample model
Let's first register a sample model for use with this notebook:
In a browser, log in to ValidMind.
In the left sidebar, navigate to Inventory and click + Register Model.
Enter the model details and click Next > to continue to assignment of model stakeholders. (Need more help?)
For example, to register a model for use with this notebook, select the following use case:
Credit Risk - CECLSelect your own name under the MODEL OWNER drop-down.
Click Register Model to add the model to your inventory.
Apply documentation template
Once you've registered your model, let's select a documentation template. A template predefines sections for your model documentation and provides a general outline to follow, making the documentation process much easier.
In the left sidebar that appears for your model, click Documents and select Documentation.
Under TEMPLATE, select
Credit Risk Scorecard.Click Use Template to apply the template.
Get your code snippet
ValidMind generates a unique code snippet for each registered model to connect with your developer environment. You initialize the ValidMind Library with this code snippet, which ensures that your documentation and tests are uploaded to the correct model when you run the notebook.
- On the left sidebar that appears for your model, select Getting Started and click Copy snippet to clipboard.
- Next, load your model identifier credentials from an
.envfile or replace the placeholder with your own code snippet:
# Load your model identifier credentials from an `.env` file
%load_ext dotenv
%dotenv .env
# Or replace with your code snippet
import validmind as vm
vm.init(
# api_host="...",
# api_key="...",
# api_secret="...",
# model="...",
)Initialize the Python environment
Then, let's import the necessary libraries and set up your Python environment for data analysis:
- Install OpenPyPL (openpyxl) which will allow us to read and write
.xlsxfiles. - Import
pandas, a Python library for data manipulation and analytics, as an alias. - Enable
matplotlib, a plotting library used for visualizing data. Ensures that any plots you generate will render inline in our notebook output rather than opening in a separate window.
%pip install openpyxl
import pandas as pd
%matplotlib inlinePreview the documentation template
Let's verify that you have connected the ValidMind Library to the ValidMind Platform and that the appropriate template is selected for your model.
You will upload documentation and test results unique to your model based on this template later on. For now, take a look at the default structure that the template provides with the vm.preview_template() function from the ValidMind library and note the empty sections:
vm.preview_template()Load the sample datasets
Let's import our sample dataset in the form of an Excel workbook (CreditRiskData.xlsx) with five sheets indexed 0 to 3, each representing a different stage of data preparation:
- Raw Data – The original unprocessed dataset.
- Preprocessed Data – A cleaned and prepared version of the raw data.
- Train Data – A training subset used to fit your model.
- Test Data – A testing subset used to evaluate model performance.
Load the raw dataset
We'll start by loading the Raw Data sheet (index 0) into a Pandas DataFrame:
df = pd.read_excel('CreditRiskData.xlsx', sheet_name=0,engine='openpyxl')
df.head()Load the preprocessed dataset
Next, load the Preprocessed Data sheet (index 1), containing cleaned inputs ready for scoring:
preprocess_df = pd.read_excel('CreditRiskData.xlsx', sheet_name=1,engine='openpyxl')
preprocess_df.head()Load the training and test datasets
Finally, load the split training (Train Data, index 2) and testing (Test Data, index 3) sets:
train_df = pd.read_excel('CreditRiskData.xlsx', sheet_name=2,engine='openpyxl')
test_df = pd.read_excel('CreditRiskData.xlsx', sheet_name=3,engine='openpyxl')Initialize the ValidMind datasets
Before you can run tests with your loaded datasets, you must first initialize a ValidMind Dataset object using the init_dataset function from the ValidMind (vm) module. This step is always necessary every time you want to connect a dataset to documentation and produce test results through ValidMind, but you only need to do it once per dataset.
For this example, we'll pass in the following arguments:
dataset: The input DataFrame to test.input_id: A unique identifier for tracking test inputs.target_column: Required for tests that compare predictions to actual outcomes; specify the name of the column with the true values.
# Initialize the raw dataset
vm_raw_dataset = vm.init_dataset(
dataset=df,
input_id="raw_dataset",
target_column='loan_status',
)
# Initialize the preprocessed dataset
vm_preprocess_dataset = vm.init_dataset(
dataset=preprocess_df,
input_id="preprocess_dataset",
target_column='loan_status',
)
# Initialize the training dataset
vm_train_ds = vm.init_dataset(
dataset=train_df,
input_id="train_dataset",
target_column='loan_status',
)
# Initialize the testing dataset
vm_test_ds = vm.init_dataset(
dataset=test_df,
input_id="test_dataset",
target_column='loan_status',
)Initialize a model object
In this Excel-based use case, predictions are precomputed and included in the Excel file. While there's no model logic to run, a ValidMind model object (vm_model) is still required for passing to other functions for analysis and tests on the data.
Simply define a placeholder model using init_model():
# Prediction logic placeholder
def dummy(X, **kwargs):
return None
xgb_model = vm.init_model(
input_id="xgb_model",
predict_fn=dummy
)Link predictions
Once the model has been registered, you can assign model predictions to the training and testing datasets.
Use the assign_predictions() method from the Dataset object to link the prediction values and probabilities from the relevant columns on our Excel spreadsheet to the training and testing datasets:
vm_train_ds.assign_predictions(model=xgb_model, prediction_column="xgb_model_prediction",probability_column='xgb_model_probabilities')
vm_test_ds.assign_predictions(model=xgb_model, prediction_column="xgb_model_prediction",probability_column='xgb_model_probabilities')Running tests
This is where it all comes together — we'll use our previously initialized datasets as inputs to run tests, then log the results to the ValidMind Platform.
We'll run some tests that are defined out-of-the-box by the template we previewed earlier in this notebook, as well as some additional tests for more evidence. For the example in this section, we've selected and defined the tests for you.
Want to learn more about navigating ValidMind tests?
Refer to our notebook outlining the utilities available for viewing and understanding available ValidMind tests: Explore tests
Refer to our notebook outlining the utilities available for viewing and understanding available ValidMind tests: Explore tests
Enable custom context for test descriptions
When you run ValidMind tests, test descriptions are automatically generated with LLM using the test results, the test name, and the static test definitions provided in the test’s docstring. While this metadata offers valuable high-level overviews of tests, insights produced by the LLM-based descriptions may not always align with your specific use cases or incorporate organizational policy requirements.
Before we run our tests, we'll include some custom use case context to improve the clarity, structure, and interpretability of the test descriptions returned. By default, custom context for LLM-generated descriptions is disabled, meaning that the output will not include any additional context. To enable custom use case context, set the VALIDMIND_LLM_DESCRIPTIONS_CONTEXT_ENABLED environment variable to 1.
This is a global setting that will affect all tests for your linked model:
import os
os.environ["VALIDMIND_LLM_DESCRIPTIONS_CONTEXT_ENABLED"] = "1"
context = """
FORMAT FOR THE LLM DESCRIPTIONS:
**<Test Name>** is designed to <begin with a concise overview of what the test does and its primary purpose,
extracted from the test description>.
The test operates by <write a paragraph about the test mechanism, explaining how it works and what it measures.
Include any relevant formulas or methodologies mentioned in the test description.>
The primary advantages of this test include <write a paragraph about the test's strengths and capabilities,
highlighting what makes it particularly useful for specific scenarios.>
Users should be aware that <write a paragraph about the test's limitations and potential risks.
Include both technical limitations and interpretation challenges.
If the test description includes specific signs of high risk, incorporate these here.>
**Key Insights:**
The test results reveal:
- **<insight title>**: <comprehensive description of one aspect of the results>
- **<insight title>**: <comprehensive description of another aspect>
...
Based on these results, <conclude with a brief paragraph that ties together the test results with the test's
purpose and provides any final recommendations or considerations.>
ADDITIONAL INSTRUCTIONS:
Present insights in order from general to specific, with each insight as a single bullet point with bold title.
For each metric in the test results, include in the test overview:
- The metric's purpose and what it measures
- Its mathematical formula
- The range of possible values
- What constitutes good/bad performance
- How to interpret different values
Each insight should progressively cover:
1. Overall scope and distribution
2. Complete breakdown of all elements with specific values
3. Natural groupings and patterns
4. Comparative analysis between datasets/categories
5. Stability and variations
6. Notable relationships or dependencies
Remember:
- Keep all insights at the same level (no sub-bullets or nested structures)
- Make each insight complete and self-contained
- Include specific numerical values and ranges
- Cover all elements in the results comprehensively
- Maintain clear, concise language
- Use only "- **Title**: Description" format for insights
- Progress naturally from general to specific observations
""".strip()
os.environ["VALIDMIND_LLM_DESCRIPTIONS_CONTEXT"] = contextDefine tests to run
First, we'll specify all the tests we'd like to independently run in a dictionary called test_config, including information about the params and inputs that each test requires.
- Note here that
inputsandinput_gridexpect theinput_idof the dataset or model as the value rather than the variable name we specified**. - When running individual tests, you can use a custom
result_idto tag the individual result with a unique identifier by appending thisresult_idto thetest_idwith a:separator. (Example::raw_datafor tests run with our raw dataset.)
test_config = {
# Data validation tests run with raw dataset
'validmind.data_validation.DatasetDescription:raw_data': {
'inputs': {'dataset': 'raw_dataset'}
},
'validmind.data_validation.DescriptiveStatistics:raw_data': {
'inputs': {'dataset': 'raw_dataset'}
},
'validmind.data_validation.MissingValues:raw_data': {
'inputs': {'dataset': 'raw_dataset'},
'params': {'min_threshold': 1}
},
'validmind.data_validation.ClassImbalance:raw_data': {
'inputs': {'dataset': 'raw_dataset'},
'params': {'min_percent_threshold': 10}
},
'validmind.data_validation.Duplicates:raw_data': {
'inputs': {'dataset': 'raw_dataset'},
'params': {'min_threshold': 1}
},
'validmind.data_validation.HighCardinality:raw_data': {
'inputs': {'dataset': 'raw_dataset'},
'params': {
'num_threshold': 100,
'percent_threshold': 0.1,
'threshold_type': 'percent'
}
},
'validmind.data_validation.Skewness:raw_data': {
'inputs': {'dataset': 'raw_dataset'},
'params': {'max_threshold': 1}
},
'validmind.data_validation.UniqueRows:raw_data': {
'inputs': {'dataset': 'raw_dataset'},
'params': {'min_percent_threshold': 1}
},
'validmind.data_validation.TooManyZeroValues:raw_data': {
'inputs': {'dataset': 'raw_dataset'},
'params': {'max_percent_threshold': 0.03}
},
'validmind.data_validation.IQROutliersTable:raw_data': {
'inputs': {'dataset': 'raw_dataset'},
'params': {'threshold': 5}
},
# Data validation tests run with preprocessed dataset
'validmind.data_validation.DescriptiveStatistics:preprocessed_data': {
'inputs': {'dataset': 'preprocess_dataset'}
},
'validmind.data_validation.TabularDescriptionTables:preprocessed_data': {
'inputs': {'dataset': 'preprocess_dataset'}
},
'validmind.data_validation.MissingValues:preprocessed_data': {
'inputs': {'dataset': 'preprocess_dataset'},
'params': {'min_threshold': 1}
},
'validmind.data_validation.TabularNumericalHistograms:preprocessed_data': {
'inputs': {'dataset': 'preprocess_dataset'}
},
'validmind.data_validation.TabularCategoricalBarPlots:preprocessed_data': {
'inputs': {'dataset': 'preprocess_dataset'}
},
'validmind.data_validation.TargetRateBarPlots:preprocessed_data': {
'inputs': {'dataset': 'preprocess_dataset'},
'params': {'default_column': 'loan_status'}
},
'validmind.data_validation.WOEBinTable': {
'input_grid': {'dataset': ['preprocess_dataset']},
'params': {
'breaks_adj': {
'loan_amnt': [5000, 10000, 15000, 20000, 25000],
'int_rate': [10, 15, 20],
'annual_inc': [50000, 100000, 150000]
}
}
},
'validmind.data_validation.WOEBinPlots': {
'input_grid': {'dataset': ['preprocess_dataset']},
'params': {
'breaks_adj': {
'loan_amnt': [5000, 10000, 15000, 20000, 25000],
'int_rate': [10, 15, 20],
'annual_inc': [50000, 100000, 150000]
}
}
},
# Data validation tests run with training & testing datasets
'validmind.data_validation.DescriptiveStatistics:development_data': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset']}
},
'validmind.data_validation.TabularDescriptionTables:development_data': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset']}
},
'validmind.data_validation.ClassImbalance:development_data': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset']},
'params': {'min_percent_threshold': 10}
},
'validmind.data_validation.UniqueRows:development_data': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset']},
'params': {'min_percent_threshold': 1}
},
'validmind.data_validation.TabularNumericalHistograms:development_data': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset']}
},
'validmind.data_validation.MutualInformation:development_data': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset']},
'params': {'min_threshold': 0.01}
},
'validmind.data_validation.PearsonCorrelationMatrix:development_data': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset']}
},
'validmind.data_validation.HighPearsonCorrelation:development_data': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset']},
'params': {'max_threshold': 0.3, 'top_n_correlations': 10}
},
'validmind.data_validation.ScoreBandDefaultRates:development_data': {
'input_grid': {'dataset': ['train_dataset'], 'model': ['xgb_model']},
'params': {'score_column': 'xgb_scores', 'score_bands': [504, 537, 570]}
},
'validmind.data_validation.DatasetSplit:development_data': {
'inputs': {'datasets': ['train_dataset', 'test_dataset']}
},
# Model validation tests
'validmind.model_validation.statsmodels.GINITable': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset'], 'model': ['xgb_model']}
},
'validmind.model_validation.sklearn.ClassifierPerformance': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset'], 'model': ['xgb_model']}
},
'validmind.model_validation.sklearn.TrainingTestDegradation:XGBoost': {
'inputs': {
'datasets': ['train_dataset', 'test_dataset'],
'model': 'xgb_model'
},
'params': {'max_threshold': 0.1}
},
'validmind.model_validation.sklearn.ROCCurve': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset'], 'model': ['xgb_model']}
},
'validmind.model_validation.sklearn.MinimumROCAUCScore': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset'], 'model': ['xgb_model']},
'params': {'min_threshold': 0.5}
},
'validmind.model_validation.statsmodels.PredictionProbabilitiesHistogram': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset'], 'model': ['xgb_model']}
},
'validmind.model_validation.statsmodels.CumulativePredictionProbabilities': {
'input_grid': {'model': ['xgb_model'], 'dataset': ['train_dataset', 'test_dataset']}
},
'validmind.model_validation.sklearn.PopulationStabilityIndex': {
'inputs': {
'datasets': ['train_dataset', 'test_dataset'],
'model': 'xgb_model'
},
'params': {'num_bins': 10, 'mode': 'fixed'}
},
'validmind.model_validation.sklearn.ConfusionMatrix': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset'], 'model': ['xgb_model']}
},
'validmind.model_validation.sklearn.MinimumAccuracy': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset'], 'model': ['xgb_model']},
'params': {'min_threshold': 0.7}
},
'validmind.model_validation.sklearn.MinimumF1Score': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset'], 'model': ['xgb_model']},
'params': {'min_threshold': 0.5}
},
'validmind.model_validation.sklearn.PrecisionRecallCurve': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset'], 'model': ['xgb_model']}
},
'validmind.model_validation.sklearn.CalibrationCurve': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset'], 'model': ['xgb_model']}
},
'validmind.model_validation.sklearn.ClassifierThresholdOptimization': {
'inputs': {'dataset': 'train_dataset', 'model': 'xgb_model'},
'params': {'target_recall': 0.8}
},
'validmind.model_validation.statsmodels.ScorecardHistogram': {
'input_grid': {'dataset': ['train_dataset', 'test_dataset']},
'params': {'score_column': 'xgb_scores'}
},
'validmind.model_validation.sklearn.ScoreProbabilityAlignment': {
'input_grid': {'dataset': ['train_dataset'], 'model': ['xgb_model']},
'params': {'score_column': 'xgb_scores'}
},
'validmind.model_validation.sklearn.WeakspotsDiagnosis': {
'inputs': {'datasets': ['train_dataset', 'test_dataset'], 'model': 'xgb_model'}
},
'validmind.model_validation.sklearn.OverfitDiagnosis': {
'inputs': {'model': 'xgb_model', 'datasets': ['train_dataset', 'test_dataset']},
'params': {'cut_off_threshold': 0.04}
},
'validmind.model_validation.sklearn.RobustnessDiagnosis': {
'inputs': {'datasets': ['train_dataset', 'test_dataset'], 'model': 'xgb_model'},
'params': {
'scaling_factor_std_dev_list': [0.1, 0.2, 0.3, 0.4, 0.5],
'performance_decay_threshold': 0.05
}
},
'validmind.model_validation.FeaturesAUC': {
'input_grid': {'model': ['xgb_model'], 'dataset': ['train_dataset', 'test_dataset']}
}
}Run defined tests
Then, we'll define a utility wrapper around the run_test function provided by the validmind.tests module in a function called run_doc_tests.
- Every test result returned by the
run_test()function has a.log()method that can be used to send the test results to the ValidMind Platform. - Our function requires information about the inputs to use on every test — which is why we specified these inputs above in
test_config.
def run_doc_tests(test_config):
for test_name, test_cfg in test_config.items():
print(test_name)
try:
# Collect available keyword arguments
kwargs = {
key: test_cfg[key]
for key in ("params", "input_grid", "inputs")
if key in test_cfg
}
kwargs["show"] = False
# Execute the test and log the results
vm.tests.run_test(test_name, **kwargs).log()
except Exception as e:
print(f"Error running test {test_name}: {e}")Finally, we can pass the input configuration to run_doc_tests and run the full suite of tests!
The variable full_suite then holds the result of these tests:
full_suite = run_doc_tests(test_config)
Note the outputs returned indicating that certain test-driven blocks don't currently exist in your model's documentation for this particular test ID.
That's expected, as when we run individual tests not defined by the documentation template out-of-the-box, the results logged need to be manually added to your documentation within the ValidMind Platform.
That's expected, as when we run individual tests not defined by the documentation template out-of-the-box, the results logged need to be manually added to your documentation within the ValidMind Platform.
Next steps
You can look at the results of this test suite right in the notebook where you ran the code, as you would expect. But there is a better way, use the ValidMind Platform to work with your model documentation.
Work with your model documentation
From the Inventory in the ValidMind Platform, go to the model you registered earlier. (Need more help?)
In the left sidebar that appears for your model, click Documentation under Documents.
What you see is the full draft of your model documentation in a more easily consumable version. From here, you can make qualitative edits to model documentation, view guidelines, collaborate with validators, and submit your model documentation for approval when it's ready.
Expand the following section to review tests automatically inserted into your documentation template: 2.3. Feature Selection and Engineering
Add individual test results to documentation
Let's also add our additional test results into the documentation. These were results sent by individual tests not defined out-of-the-box by our template. For example (Need more help?):
Locate the Data Preparation section of your documentation and click on 2.2. Correlations and Interactions to expand that section.
Hover under the Pearson Correlation Matrix content block until a horizontal dashed line with a + button appears, indicating that you can insert a new block.
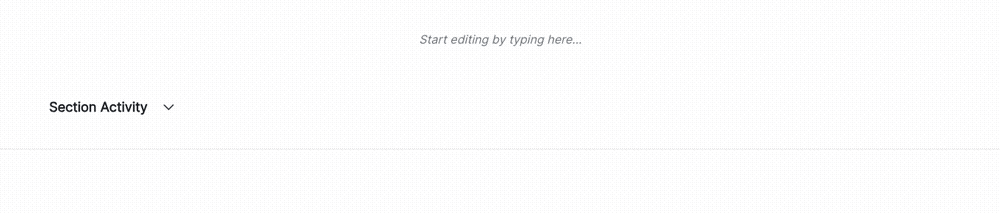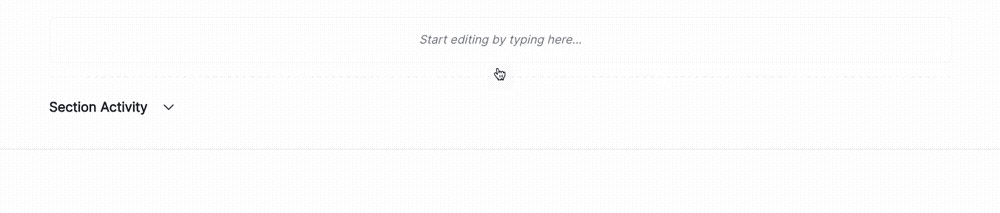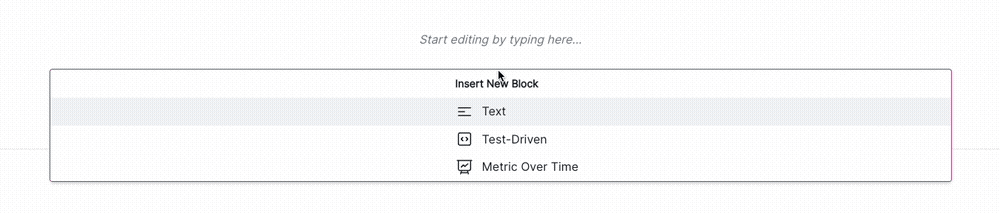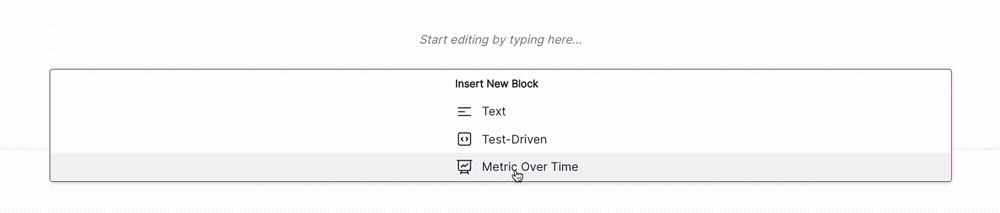
Click + and then select Test-Driven Block under FROM LIBRARY:
- Click on VM Library under TEST-DRIVEN in the left sidebar.
- In the search bar, type in
HighPearsonCorrelation. - Select
HighPearsonCorrelation:development_dataas the test.
Finally, click Insert 1 Test Result to Document to add the test result to the documentation.
Confirm that the individual results for the high correlation test has been correctly inserted into section 2.3. Correlations and Interactions of the documentation.
Discover more learning resources
We offer many interactive notebooks to help you document models:
Or, visit our documentation to learn more about ValidMind.
Upgrade ValidMind
After installing ValidMind, you’ll want to periodically make sure you are on the latest version to access any new features and other enhancements.
Retrieve the information for the currently installed version of ValidMind:
%pip show validmindIf the version returned is lower than the version indicated in our production open-source code, restart your notebook and run:
%pip install --upgrade validmindYou may need to restart your kernel after running the upgrade package for changes to be applied.