# Make sure the ValidMind Library is installed
%pip install -q validmind
# Load your model identifier credentials from an `.env` file
%load_ext dotenv
%dotenv .env
# Or replace with your code snippet
import validmind as vm
vm.init(
# api_host="...",
# api_key="...",
# api_secret="...",
# model="...",
document="validation-report",
)ValidMind for model validation 3 — Developing a potential challenger model
Learn how to use ValidMind for your end-to-end model validation process with our series of four introductory notebooks. In this third notebook, develop a potential challenger model and then pass your model and its predictions to ValidMind.
A challenger model is an alternate model that attempts to outperform the champion model, ensuring that the best performing fit-for-purpose model is always considered for deployment. Challenger models also help avoid over-reliance on a single model, and allow testing of new features, algorithms, or data sources without disrupting the production lifecycle.
Learn by doing
Our course tailor-made for validators new to ValidMind combines this series of notebooks with more a more in-depth introduction to the ValidMind Platform — Validator Fundamentals
Our course tailor-made for validators new to ValidMind combines this series of notebooks with more a more in-depth introduction to the ValidMind Platform — Validator Fundamentals
Prerequisites
In order to develop potential challenger models with this notebook, you'll need to first have:
Need help with the above steps?
Refer to the first two notebooks in this series:
Setting up
This section should be quite familiar to you — as we performed the same actions in the previous notebook, 2 — Start the model validation process.
Initialize the ValidMind Library
As usual, let's first connect up the ValidMind Library to our model we previously registered in the ValidMind Platform:
- On the left sidebar that appears for your model, select Getting Started and select
Validationfrom the DOCUMENT drop-down menu. - Click Copy snippet to clipboard.
- Next, load your model identifier credentials from an
.envfile or replace the placeholder with your own code snippet:
Import the sample dataset
Next, we'll load in the sample Bank Customer Churn Prediction dataset used to develop the champion model that we will independently preprocess:
# Load the sample dataset
from validmind.datasets.classification import customer_churn as demo_dataset
print(
f"Loaded demo dataset with: \n\n\t• Target column: '{demo_dataset.target_column}' \n\t• Class labels: {demo_dataset.class_labels}"
)
raw_df = demo_dataset.load_data()Preprocess the dataset
We’ll apply a simple rebalancing technique to the dataset before continuing:
import pandas as pd
raw_copy_df = raw_df.sample(frac=1) # Create a copy of the raw dataset
# Create a balanced dataset with the same number of exited and not exited customers
exited_df = raw_copy_df.loc[raw_copy_df["Exited"] == 1]
not_exited_df = raw_copy_df.loc[raw_copy_df["Exited"] == 0].sample(n=exited_df.shape[0])
balanced_raw_df = pd.concat([exited_df, not_exited_df])
balanced_raw_df = balanced_raw_df.sample(frac=1, random_state=42)Let’s also quickly remove highly correlated features from the dataset using the output from a ValidMind test.
As you know, before we can run tests you’ll need to initialize a ValidMind dataset object with the init_dataset function:
# Register new data and now 'balanced_raw_dataset' is the new dataset object of interest
vm_balanced_raw_dataset = vm.init_dataset(
dataset=balanced_raw_df,
input_id="balanced_raw_dataset",
target_column="Exited",
)With our balanced dataset initialized, we can then run our test and utilize the output to help us identify the features we want to remove:
# Run HighPearsonCorrelation test with our balanced dataset as input and return a result object
corr_result = vm.tests.run_test(
test_id="validmind.data_validation.HighPearsonCorrelation",
params={"max_threshold": 0.3},
inputs={"dataset": vm_balanced_raw_dataset},
)# From result object, extract table from `corr_result.tables`
features_df = corr_result.tables[0].data
features_df# Extract list of features that failed the test
high_correlation_features = features_df[features_df["Pass/Fail"] == "Fail"]["Columns"].tolist()
high_correlation_features# Extract feature names from the list of strings
high_correlation_features = [feature.split(",")[0].strip("()") for feature in high_correlation_features]
high_correlation_featuresWe can then re-initialize the dataset with a different input_id and the highly correlated features removed and re-run the test for confirmation:
# Remove the highly correlated features from the dataset
balanced_raw_no_age_df = balanced_raw_df.drop(columns=high_correlation_features)
# Re-initialize the dataset object
vm_raw_dataset_preprocessed = vm.init_dataset(
dataset=balanced_raw_no_age_df,
input_id="raw_dataset_preprocessed",
target_column="Exited",
)# Re-run the test with the reduced feature set
corr_result = vm.tests.run_test(
test_id="validmind.data_validation.HighPearsonCorrelation",
params={"max_threshold": 0.3},
inputs={"dataset": vm_raw_dataset_preprocessed},
)Split the preprocessed dataset
With our raw dataset rebalanced with highly correlated features removed, let's now spilt our dataset into train and test in preparation for model evaluation testing:
# Encode categorical features in the dataset
balanced_raw_no_age_df = pd.get_dummies(
balanced_raw_no_age_df, columns=["Geography", "Gender"], drop_first=True
)
balanced_raw_no_age_df.head()from sklearn.model_selection import train_test_split
# Split the dataset into train and test
train_df, test_df = train_test_split(balanced_raw_no_age_df, test_size=0.20)
X_train = train_df.drop("Exited", axis=1)
y_train = train_df["Exited"]
X_test = test_df.drop("Exited", axis=1)
y_test = test_df["Exited"]# Initialize the split datasets
vm_train_ds = vm.init_dataset(
input_id="train_dataset_final",
dataset=train_df,
target_column="Exited",
)
vm_test_ds = vm.init_dataset(
input_id="test_dataset_final",
dataset=test_df,
target_column="Exited",
)Import the champion model
With our raw dataset assessed and preprocessed, let's go ahead and import the champion model submitted by the model development team in the format of a .pkl file: lr_model_champion.pkl
# Import the champion model
import pickle as pkl
with open("lr_model_champion.pkl", "rb") as f:
log_reg = pkl.load(f)Training a potential challenger model
We're curious how an alternate model compares to our champion model, so let's train a challenger model as a basis for our testing.
Our champion logistic regression model is a simpler, parametric model that assumes a linear relationship between the independent variables and the log-odds of the outcome. While logistic regression may not capture complex patterns as effectively, it offers a high degree of interpretability and is easier to explain to stakeholders. However, model risk is not calculated in isolation from a single factor, but rather in consideration with trade-offs in predictive performance, ease of interpretability, and overall alignment with business objectives.
Random forest classification model
A random forest classification model is an ensemble machine learning algorithm that uses multiple decision trees to classify data. In ensemble learning, multiple models are combined to improve prediction accuracy and robustness.
Random forest classification models generally have higher accuracy because they capture complex, non-linear relationships, but as a result they lack transparency in their predictions.
# Import the Random Forest Classification model
from sklearn.ensemble import RandomForestClassifier
# Create the model instance with 50 decision trees
rf_model = RandomForestClassifier(
n_estimators=50,
random_state=42,
)
# Train the model
rf_model.fit(X_train, y_train)Initializing the model objects
Initialize the model objects
In addition to the initialized datasets, you'll also need to initialize a ValidMind model object (vm_model) that can be passed to other functions for analysis and tests on the data for each of our two models.
You simply initialize this model object with vm.init_model():
# Initialize the champion logistic regression model
vm_log_model = vm.init_model(
log_reg,
input_id="log_model_champion",
)
# Initialize the challenger random forest classification model
vm_rf_model = vm.init_model(
rf_model,
input_id="rf_model",
)Assign predictions
With our models registered, we'll move on to assigning both the predictive probabilities coming directly from each model's predictions, and the binary prediction after applying the cutoff threshold described in the Compute binary predictions step above.
- The
assign_predictions()method from theDatasetobject can link existing predictions to any number of models. - This method links the model's class prediction values and probabilities to our
vm_train_dsandvm_test_dsdatasets.
If no prediction values are passed, the method will compute predictions automatically:
# Champion — Logistic regression model
vm_train_ds.assign_predictions(model=vm_log_model)
vm_test_ds.assign_predictions(model=vm_log_model)
# Challenger — Random forest classification model
vm_train_ds.assign_predictions(model=vm_rf_model)
vm_test_ds.assign_predictions(model=vm_rf_model)Running model evaluation tests
With our setup complete, let's run the rest of our validation tests. Since we have already verified the data quality of the dataset used to train our champion model, we will now focus on comprehensive performance evaluations of both the champion and challenger models.
Run model performance tests
Let's run some performance tests, beginning with independent testing of our champion logistic regression model, then moving on to our potential challenger model.
Use vm.tests.list_tests() to identify all the model performance tests for classification:
vm.tests.list_tests(tags=["model_performance"], task="classification")We'll isolate the specific tests we want to run in mpt:
As we learned in the previous notebook 2 — Start the model validation process, you can use a custom result_id to tag the individual result with a unique identifier by appending this result_id to the test_id with a : separator. We'll append an identifier for our champion model here:
mpt = [
"validmind.model_validation.sklearn.ClassifierPerformance:logreg_champion",
"validmind.model_validation.sklearn.ConfusionMatrix:logreg_champion",
"validmind.model_validation.sklearn.MinimumAccuracy:logreg_champion",
"validmind.model_validation.sklearn.MinimumF1Score:logreg_champion",
"validmind.model_validation.sklearn.ROCCurve:logreg_champion"
]Evaluate performance of the champion model
Now, let's run and log our batch of model performance tests using our testing dataset (vm_test_ds) for our champion model:
- The test set serves as a proxy for real-world data, providing an unbiased estimate of model performance since it was not used during training or tuning.
- The test set also acts as protection against selection bias and model tweaking, giving a final, more unbiased checkpoint.
for test in mpt:
vm.tests.run_test(
test,
inputs={
"dataset": vm_test_ds, "model" : vm_log_model,
},
).log()
Note the output returned indicating that a test-driven block doesn't currently exist in your model's documentation for some test IDs.
That's expected, as when we run validations tests the results logged need to be manually added to your report as part of your compliance assessment process within the ValidMind Platform.
That's expected, as when we run validations tests the results logged need to be manually added to your report as part of your compliance assessment process within the ValidMind Platform.
Log an artifact
As we can observe from the output above, our champion model doesn't pass the MinimumAccuracy based on the default thresholds of the out-of-the-box test, so let's log an artifact (finding) in the ValidMind Platform (Need more help?):
From the Inventory in the ValidMind Platform, go to the model you connected to earlier.
In the left sidebar that appears for your model, click Validation under Documents.
Locate the Data Preparation section and click on 2.2.2. Model Performance to expand that section.
Under the Model Performance Metrics section, locate Artifacts then click Link Artifact to Report:
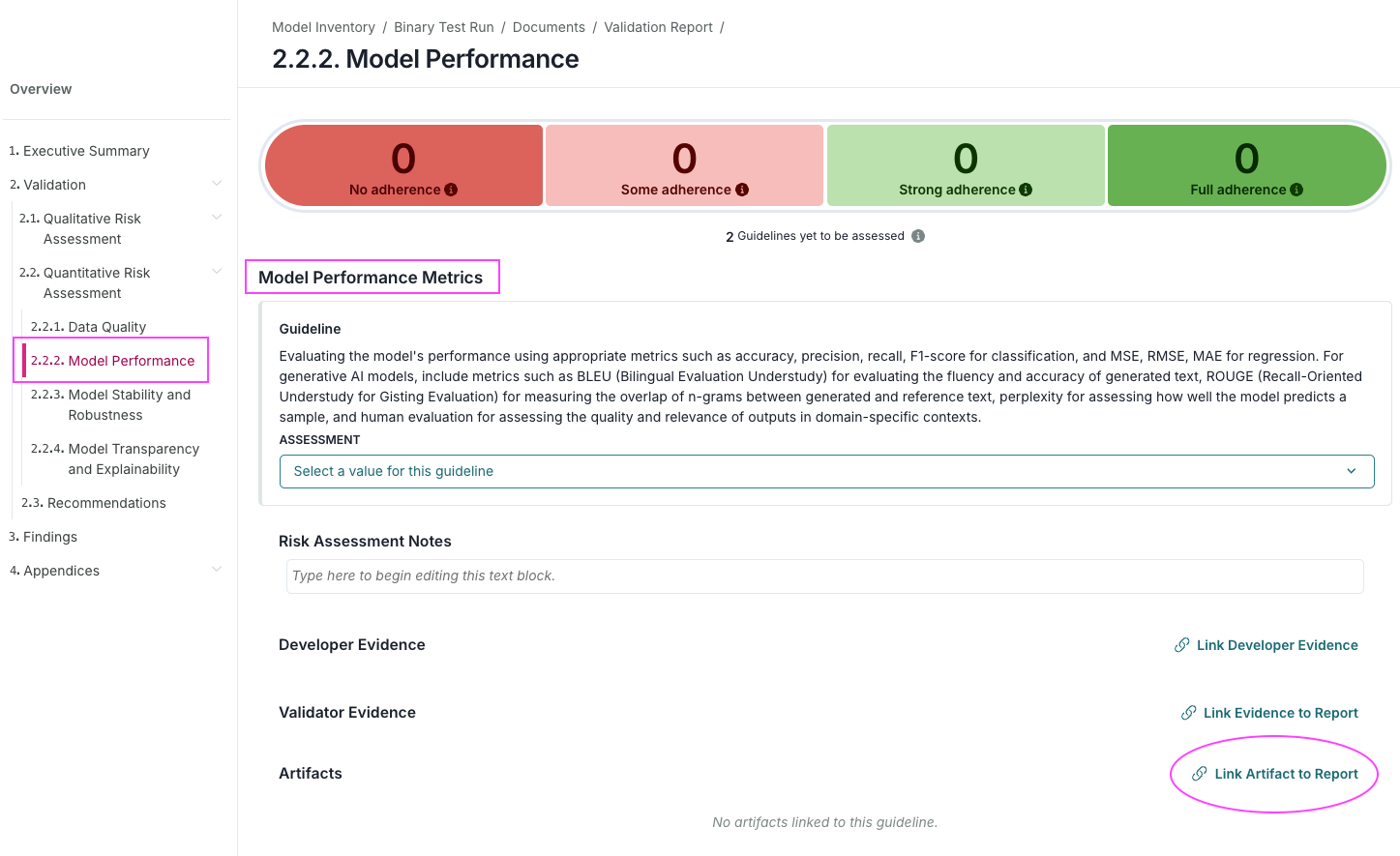
Select Validation Issue as the type of artifact.
Click + Add Validation Issue to add a validation issue type artifact.
Enter in the details for your validation issue, for example:
- TITLE — Champion Logistic Regression Model Fails Minimum Accuracy Threshold
- RISK AREA — Model Performance
- DOCUMENTATION SECTION — 3.2. Model Evaluation
- DESCRIPTION — The logistic regression champion model was subjected to a Minimum Accuracy test to determine whether its predictive accuracy meets the predefined performance threshold of 0.7. The model achieved an accuracy score of 0.6136, which falls below the required minimum. As a result, the test produced a Fail outcome.
Click Save.
Select the validation issue you just added to link to your validation report and click Update Linked Artifacts to insert your validation issue.
Click on the validation issue to expand the issue, where you can adjust details such as severity, owner, due date, status, etc. as well as include proposed remediation plans or supporting documentation as attachments.
Evaluate performance of challenger model
We've now conducted similar tests as the model development team for our champion model, with the aim of verifying their test results.
Next, let's see how our challenger models compare. We'll use the same batch of tests here as we did in mpt, but append a different result_id to indicate that these results should be associated with our challenger model:
mpt_chall = [
"validmind.model_validation.sklearn.ClassifierPerformance:champion_vs_challenger",
"validmind.model_validation.sklearn.ConfusionMatrix:champion_vs_challenger",
"validmind.model_validation.sklearn.MinimumAccuracy:champion_vs_challenger",
"validmind.model_validation.sklearn.MinimumF1Score:champion_vs_challenger",
"validmind.model_validation.sklearn.ROCCurve:champion_vs_challenger"
]We'll run each test once for each model with the same vm_test_ds dataset to compare them:
for test in mpt_chall:
vm.tests.run_test(
test,
input_grid={
"dataset": [vm_test_ds], "model" : [vm_log_model,vm_rf_model]
}
).log()
Based on the performance metrics, our challenger random forest classification model passes the
In your validation report, support your recommendation in your validation issue's Proposed Remediation Plan to investigate the usage of our challenger model by inserting the performance tests we logged with this notebook into the appropriate section.
MinimumAccuracy where our champion did not. In your validation report, support your recommendation in your validation issue's Proposed Remediation Plan to investigate the usage of our challenger model by inserting the performance tests we logged with this notebook into the appropriate section.
Run diagnostic tests
Next, we want to inspect the robustness and stability testing comparison between our champion and challenger model.
Use list_tests() to list all available diagnosis tests applicable to classification tasks:
vm.tests.list_tests(tags=["model_diagnosis"], task="classification")Let’s now assess the models for potential signs of overfitting and identify any sub-segments where performance may inconsistent with the OverfitDiagnosis test.
Overfitting occurs when a model learns the training data too well, capturing not only the true pattern but noise and random fluctuations resulting in excellent performance on the training dataset but poor generalization to new, unseen data:
- Since the training dataset (
vm_train_ds) was used to fit the model, we use this set to establish a baseline performance for how well the model performs on data it has already seen. - The testing dataset (
vm_test_ds) was never seen during training, and here simulates real-world generalization, or how well the model performs on new, unseen data.
vm.tests.run_test(
test_id="validmind.model_validation.sklearn.OverfitDiagnosis:champion_vs_challenger",
input_grid={
"datasets": [[vm_train_ds,vm_test_ds]],
"model" : [vm_log_model,vm_rf_model]
}
).log()Let's also conduct robustness and stability testing of the two models with the RobustnessDiagnosis test. Robustness refers to a model's ability to maintain consistent performance, and stability refers to a model's ability to produce consistent outputs over time across different data subsets.
Again, we'll use both the training and testing datasets to establish baseline performance and to simulate real-world generalization:
vm.tests.run_test(
test_id="validmind.model_validation.sklearn.RobustnessDiagnosis:Champion_vs_LogRegression",
input_grid={
"datasets": [[vm_train_ds,vm_test_ds]],
"model" : [vm_log_model,vm_rf_model]
},
).log()Run feature importance tests
We also want to verify the relative influence of different input features on our models' predictions, as well as inspect the differences between our champion and challenger model to see if a certain model offers more understandable or logical importance scores for features.
Use list_tests() to identify all the feature importance tests for classification:
# Store the feature importance tests
FI = vm.tests.list_tests(tags=["feature_importance"], task="classification",pretty=False)
FIWe'll only use our testing dataset (vm_test_ds) here, to provide a realistic, unseen sample that mimic future or production data, as the training dataset has already influenced our model during learning:
# Run and log our feature importance tests for both models for the testing dataset
for test in FI:
vm.tests.run_test(
"".join((test,':champion_vs_challenger')),
input_grid={
"dataset": [vm_test_ds], "model" : [vm_log_model,vm_rf_model]
},
).log()In summary
In this third notebook, you learned how to:
Next steps
Finalize validation and reporting
Now that you're familiar with the basics of using the ValidMind Library to run and log validation tests, let's learn how to implement some custom tests and wrap up our validation: 4 — Finalize validation and reporting
Copyright © 2023-2026 ValidMind Inc. All rights reserved.
Refer to LICENSE for details.
SPDX-License-Identifier: AGPL-3.0 AND ValidMind Commercial